資料分析大致流程分成這幾個步驟。如下圖所示。透過圖示了解大致流程後,我們將來逐一探討每個步驟的功用及方法。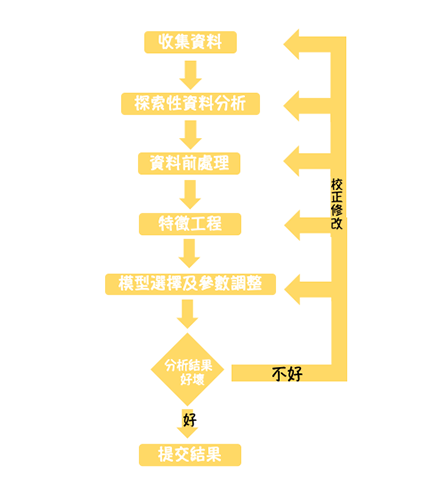
這個步驟在學生階段比較少做。因為通常參加比賽時,主辦方都會給出完整的資料讓你去做分析。但未來到外面工作後,這個階段就很重要了。你必須要很清楚現階段公司或廠商需要分析什麼、做出什麼。若收集資料時跑偏了,就算後面分析得很強,模型用的多厲害,但主管要看到的卻不是這個。那麼公司的問題依然沒解決。
探索性資料分析其實有點類似挖寶藏的概念。透過一些統計觀念、圖表可以讓讀者迅速暸解整筆資料的架構,當你對手中握有的資料越暸解,就越清楚下一步應該怎麼做。簡單來說把資料挖得越深,就越能知道這筆資料能夠為你帶來什麼有用的資訊。
一般來說探索性資料分析一般透過畫圖或統計方法來做。透過此步驟能夠比較容易讀懂內容,也比較容易解釋給其他人聽。因此詳細的實作部分我們會在第六篇和第七篇來做說明。
資料前處理,顧名思義就是在做資料分析前先將資料處理好。
不管是自己收集的資料或是比賽給的資料,拿到的資料不一定是完整的,有可能存在一些問題像是缺值、資料筆數過少、資料key錯,甚至他給的資料根本不是你想要的格式,若直接將這種資料丟進去做分析,那預測出來的結果一定與實際有很大的差異。因此資料前處理是資料分析中相當重要的步驟之一。
在剛入門階段,比賽、專案中最常遇到的問題不外乎就是資料缺值、資料不平衡、資料含有離群值等問題。而要如何解決這些問題,我們會在後面逐步說明。
當我們拿到一筆資料,資料中每個特徵不一定都是我們需要的,甚至有些特徵還會影響原本正確的結果,這時候就要挑選出對目標來說有用的特徵。例如統計學所提到的相關係數,就是讓我們看出資料之間的相關性,進而選出有用的特徵。當然上面敘述的是最基本的。至於還有哪些方法到後面我們也會詳細說明。
剛入門資料分析時,我們通常會套入別人寫好的模型。將整理好的資料丟入模型,模型就會給出一個預測的答案。當然隨著能力的精進,當然也必須更深入了解模型的運行,不能光靠套模型打天下。本篇的重點主要是給剛入門的新手,因此我們會告訴你們什麼樣的資料適合什麼樣的模型,讓你們動手去完成一個簡單的專案。
因為模型預測出來的結果是預測值,所以一定會存在著誤差,我們要怎麼去看預測結果的好壞,就是結果分析的目的。以機器學習來說資料分為回歸與分類兩大類的問題,兩者的評估指標也不太相同,至於怎麼使用,我們到後面會搭配案例來詳細說明。
透過上述這些步驟是不是稍微了解人們口中的資料分析在幹嘛了呢?照著這個流程學習就能夠完成線上大部分的比賽了,那麼我們接下來要介紹的就是各個步驟的方法,繼續看下去吧~

